ELF32 파일이다. 아이다로 열면 entry point 에러가 난다.
gdb 로 열면 이상한곳에 와있다. 실행시키면 Access Denied 가 출력되고 끝난다.

strace 로 확인한 결과이다. getuid32() 함수를 호출해 uid 를 가져온 뒤, Access Denied 가 출력되는걸 보면,
root 로 실행해야한다는 합리적의심이 가능하다!

sudo strace ./SimpleVM
getuid32() 결과가 0이고, Input 이라고 출력되는 것을 볼 수 있다. helloworld! 을 입력했더니 Wrong 이라 뜬다.
패킹된 것같은데 프로세스를 덤프해서 정적분석해보자.
procdump 리눅스버전을 쓸 수도 있고, gcore 으로 간단하게 할 수 있다.
터미널 2개를 띄우자 (터미널1, 터미널2 로 이름짓겠다)
터미널 1에서 $ sudo ./SimpleVM 을 실행해 입력하지말고 기다린다.
터미널 2에서 $ ps -al 으로 SimpleVM 의 PID 를 확인한 뒤, $ sudo gcore (PID) 를 입력해 코어파일을 덤프하자.
이제 아이다로 열어서 분석하면 된다!
이 때 부모프로세스를 덤프하던, 자식프로세스를 덤프하던 상관이 없다.
core 파일을 ida 로 열어서 분석하자.

shift+f12 를 눌러 string table 에서 "input :" 문자열을 클릭해, XREF (문자열이 참조된곳) 으로 이동한다.
main+6E 라고 써진 부분이 main 함수이다.
실제로 열어보면 0x804556 으로 되어있을 것이다. (직접 수정했기 때문)
plt 가 다 깨져있어 함수 이름을 확인할 수 없다.
aslr 끄고 다시 덤프해서 gdb로 함수주소를 확인할까 했는데, 생각보다 함수가 별로 없어
그냥 strace 결과 보고 수정하면 된다.
|
1
2
3
4
5
6
7
8
9
|
if ( getuid32() )
{
v11 = 0;
for ( i = 1; i <= 14; ++i )
{
v10 = byte_804B060[i - 1] ^ i;
write(1, &v10, 1); // Access Denied!
}
}
|
cs |
uid 를 가져와 root 인지 비교하는 부분이다. root 아니면 Access Denied 가 출력됐던 부분이ㄷ ㅏ.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
write(1, "Input : ", 8);
pipe(&v5);
if ( v0 != -1 && (pipe(&v7), v1 != -1) ) // pipe 생성으로 자식프로세스와 통신
{
v9 = clone();
if ( v9 == -1 )
{
v11 = 0;
for ( i = 1; i <= 6; ++i )
{
v10 = byte_804B06E[i - 1] ^ i;
write(1, &v10, 1); // Error
}
}
|
cs |
root 라면, 이 부분이 실행된다. pipe 함수를 v5, v7 을 각각 인자로
pipe 통신하기위해 준비하고, clone 함수로 자식프로세스를 생성한다. 실패하면 Error
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
else // child process
{
v12 = 0;
v13 = 0;
v14 = 0;
read(0, &v12, 10);
if ( v14 )
{
v11 = 0;
for ( i = 1; i <= 6; ++i )
{
v10 = byte_804B074[i - 1] ^ i;
write(1, &v10, 1); // Wrong
}
}
else
{
write(v6, &v12, 9);
for ( i = 0; i <= 199; ++i )
{
v2 = ROL_3(*(i + 0x804B0A0), 3);
*(i + 0x804B0A0) = v2;
}
sub_8048410();
write(v6, &input, 200); // v12에 읽고, 0x804b0a0 암호화하고
// 두 개를 v6에 출력 (fd[1])
}
}
}
|
cs |
fd 0 에서 입력을 받고, 0x804B0A0 ~ 0x804B168 값들을 ROL 3 돌린다.
그리고 v6 에 출력하는데 (fd 1)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
else if ( v9 ) // parent process
{
v15 = 0;
v16 = 0;
v17 = 0;
read(v5, &v15, 9);
read(v5, &input, 200);
for ( i = 0; i <= 199; ++i )
*(i + 0x804B0A0) ^= 0x20u;
input = v15;
input_4 = v16;
for ( i = 0; i <= 199; ++i )
*(i + 0x804B0A0) ^= 0x10u;
if ( vm() == 1 )
{
v11 = 0;
for ( i = 1; i <= 6; ++i )
{
v10 = byte_804B074[i - 1] ^ i;
write(1, &v10, 1); // true
}
}
else
{
v11 = 0;
for ( i = 1; i <= 6; ++i )
{
v10 = byte_804B074[i - 1] ^ i; // false
write(1, &v10, 1);
}
}
}
|
cs |
v6에 출력된 값을, 부모프로세스에서 받아와, 0x804B0A0 영역을 XOR 20 하고,
0x804B0A0 ~ A8 에 내 입력값 8바이트를 넣고, 다시 0x804B0A0 영역을 XOR 10 한다.
그리고 vm(내가 명명) 함수를 호출해 리턴값이 1인지 검사한다.
Input : 을 출력하고, read 함수가 호출된 상태에서 덤프해온 파일이니,
'그' 영역은, 아직 암호화하지 않은 상태이다.
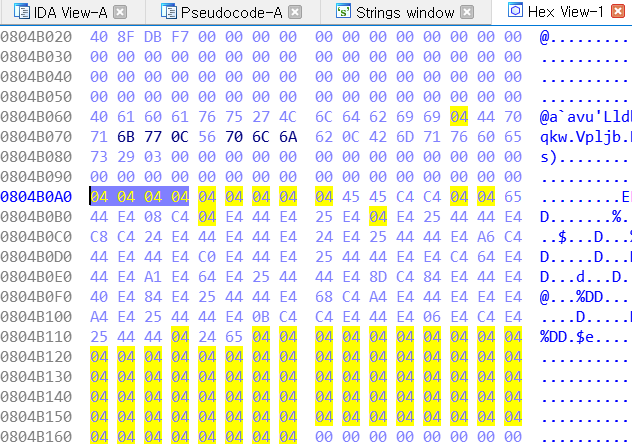
HexView 에서 그 영역에 커서를 올리고

Byte(here()+i) 으로 값을 가져올 수 있다.
|
1
2
3
4
5
6
7
8
|
ar=[4, 4, 4, 4, 4, 4, 4, 4, 4, 69, 69, 196, 196, 4, 4, 101, 68, 228, 8, 196, 4, 228, 68, 228, 37, 228, 4, 228, 37, 68, 68, 228, 200, 196, 36, 228, 68, 228, 68, 228, 36, 228, 37, 68, 68, 228, 166, 196, 68, 228, 68, 228, 192, 228, 68, 228, 37, 68, 68, 228, 228, 196, 100, 228, 68, 228, 161, 228, 100, 228, 37, 68, 68, 228, 141, 196, 132, 228, 68, 228, 64, 228, 132, 228, 37, 68, 68, 228, 104, 196, 164, 228, 68, 228, 228, 228, 164, 228, 37, 68, 68, 228, 11, 196, 196, 228, 68, 228, 6, 228, 196, 228, 37, 68, 68, 4, 36, 101, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]
def ROL3(d):
return ((d<<3)|(d>>5))&0xff
for i in range(200):
ar[i]=ROL3(ar[i])^0x30
print(ar)
[16, 16, 16, 16, 16, 16, 16, 16, 16, 26, 26, 22, 22, 16, 16, 27, 18, 23, 112, 22, 16, 23, 18, 23, 25, 23, 16, 23, 25, 18, 18, 23, 118, 22, 17, 23, 18, 23, 18, 23, 17, 23, 25, 18, 18, 23, 5, 22, 18, 23, 18, 23, 54, 23, 18, 23, 25, 18, 18, 23, 23, 22, 19, 23, 18, 23, 61, 23, 19, 23, 25, 18, 18, 23, 92, 22, 20, 23, 18, 23, 50, 23, 20, 23, 25, 18, 18, 23, 115, 22, 21, 23, 18, 23, 23, 23, 21, 23, 25, 18, 18, 23, 104, 22, 22, 23, 18, 23, 0, 23, 22, 23, 25, 18, 18, 16, 17, 27, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16] |
cs |
이제 vm 함수를 분석하자.

함수 이름은 임의로 지정한 것이다. init 함수로 그 영역에서 값을 가져와 알맞은 함수들로 switch 한다.
덤프 뜬거라 그 영역들의 값을 그대로 가져와 디컴파일해줘서, 일일이 어셈코드를 분석했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
def init():
global ar
ar[240]=ar[ar[9]^0x10]^0x10
ar[9]=(ar[9]^0x10)+1^0x10
while 1:
print(f"this is {ar[9]}")
init()
print(f"okay {ar[240]}")
if ar[240]==2: #mov
init()
ar[248]=ar[240]
init()
ar[244]=ar[240]
ar[240]=ar[248]
ar[248]=ar[244]
ar[ar[240]]=ar[248]^0x10
print(f"mov {ar[248]^0x10} to ar[{ar[240]}]")
elif ar[240]==6: #xor
ar[248]=ar[240]
ar[236]=ar[244]
init()
ar[236]=ar[240]
init()
a=ar[240]
ar[240]=ar[ar[240]]^0x10
ar[244]=ar[240]
ar[240]=ar[236]
b=ar[240]
ar[240]=ar[ar[240]]^0x10
ar[240]=ar[244]^ar[240]
print(f"xor ar[{a}] and ar[{b}] : {ar[240]}",end='')
ar[248]=ar[240]
ar[240]=ar[236]
ar[ar[240]]=ar[248]^0x10
print(f", ar[{ar[240]}]")
elif ar[240]==7: #cmp
init()
a=ar[240]
ar[240]=ar[ar[240]]^0x10
ar[248]=ar[240]
init()
b=ar[240]
ar[240]=ar[ar[240]]^0x10
ar[244]=ar[240]
if ar[248]==ar[244]:
ar[248]=1
else:
ar[248]=0
ar[ar[240]]=ar[248]^0x10
print(f"cmp ar[{a}] and ar[{b}] res in ar[{ar[240]}]={ar[ar[240]]^0x10}")
elif ar[240]==9: #jz
ar[248]=ar[240]
init()
ar[248]=ar[240]
ar[240]=8
ar[240]=ar[ar[240]]^0x10
print(f"if ar[8] ({ar[8]^0x10} is 0, ar[240]={ar[248]},ar[0xa]={ar[0xa]^0x10}+ar[240]^0x10")
if ar[240]==0:
ar[240]=ar[248]
ar[9]=(ar[0xa]^0x10)+ar[240]^0x10
elif ar[240]==10: #jump
init()
ar[9]=(ar[0xa]^0x10)+ar[240]^0x10
print(f"plus {ar[0xa]^0x10} and {ar[240]} = ar[9] ({ar[9]})")
elif ar[240]==11:
ar[240]=0
ar[240]=ar[ar[240]]^0x10
ar[248]=ar[240]
ar[240]=1
ar[240]=ar[ar[240]]^0x10
ar[244]=ar[240]
ar[240]=ar[248]
ar[248]=ar[244]
print(f"case 11, {ar[240]}, {ar[248]}")
else:
break
|
cs |
대충 이런식으로 분석했다.
switch 문 별로 해당하는 어셈코드와 같은 동작을 했다.
ar[0]~ar[6] 은 입력값으로, 비교당하고
ar[8] 은 ZF 으로, 분기여부를 결정하고
ar[9] 는 IP 로, 분기할때 사용되고,
ar[236] ~ ar[248] 은 레지스터로 사용됐다.
중간중간 0x10 과 xor 하는 이유는, 0x10 이 암호화방식이기 때문이다 ㅋㅋ
더 어려운 문제는 코드를 더 어렵게 암호화할 것같았다.
아마 값을 하나씩 가져와 제시하는 값과 입력값이 같지 않으면, 이상한곳으로 JUMP 시키는 것같다.
저 코드를 실행시켰는데, 값이 같지 않으니 실행되다가 중간에 멈춰버렸다.
그래서 어셈코드로 만들었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
ar=[4, 4, 4, 4, 4, 4, 4, 4, 4, 69, 69, 196, 196, 4, 4, 101, 68, 228, 8, 196, 4, 228, 68, 228, 37, 228, 4, 228, 37, 68, 68, 228, 200, 196, 36, 228, 68, 228, 68, 228, 36, 228, 37, 68, 68, 228, 166, 196, 68, 228, 68, 228, 192, 228, 68, 228, 37, 68, 68, 228, 228, 196, 100, 228, 68, 228, 161, 228, 100, 228, 37, 68, 68, 228, 141, 196, 132, 228, 68, 228, 64, 228, 132, 228, 37, 68, 68, 228, 104, 196, 164, 228, 68, 228, 228, 228, 164, 228, 37, 68, 68, 228, 11, 196, 196, 228, 68, 228, 6, 228, 196, 228, 37, 68, 68, 4, 36, 101, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]
def ROL3(d):
return ((d<<3)|(d>>5))&0xff
input=b'i1234567p'
for i in range(200):
ar[i]=ROL3(ar[i])^0x20
for i in range(9):
ar[i]=input[i]
for i in range(200):
ar[i]^=0x10
ar+=[0]*50
code=ar[10:]
i=0
d=[]
flag=""
while i<len(code):
if code[i]^0x10==2:
print(f"mov ar[{code[i+1]^0x10}], {code[i+2]^0x10}")
d.append(code[i+2]^0x10)
i+=3
elif code[i]^0x10==6:
print(f"xor ar[{code[i+1]^0x10}], ar[{code[i+2]^0x10}]")
i+=3
elif code[i]^0x10==7:
print(f"cmp ar[{code[i+1]^0x10}], ar[{code[i+2]^0x10}]")
i+=3
elif code[i]^0x10==9:
print(f"if zero, jump ar[8]^0x10 +ar[{code[i+1]^0x10}]")
i+=2
elif code[i]^0x10==10:
print(f"jmp {code[0]^0x10}+ar[{code[i+1]^0x10}]")
i+=2
elif code[i]^0x10==11:
print('CORRECT!\nEND')
i+=1
else:
print('END')
break
print('-'*0x15+'FLAG'+'-'*0x15)
for i in range(0,len(d)-1,2):
print(chr(d[i]^d[i+1]),end='')
print('\n'+'-'*0x30)
|
cs |
이런식으로 사용하는 인자수+1 만큼 i 값을 증가시키면서 디스어셈블 했다.

대충 보니 mov 로 옮기는 두 수를 가져와 xor 하면 알맞은 값이 나올 것같다.
cmp 로 비교하는데 jz로 이상한값으로 점프하는건 실제 어셈코드와 다르다.
이 문제에서는 값이 같으면 ZF 를 1로, 다르면 0으로 표시한다. (실제 어셈코드와 다르게)
어쨋든, mov 으로 이동하는 수들을 모아, 2개씩 짝지어서 xor 하면 알맞은 값이 나온다.

야호



